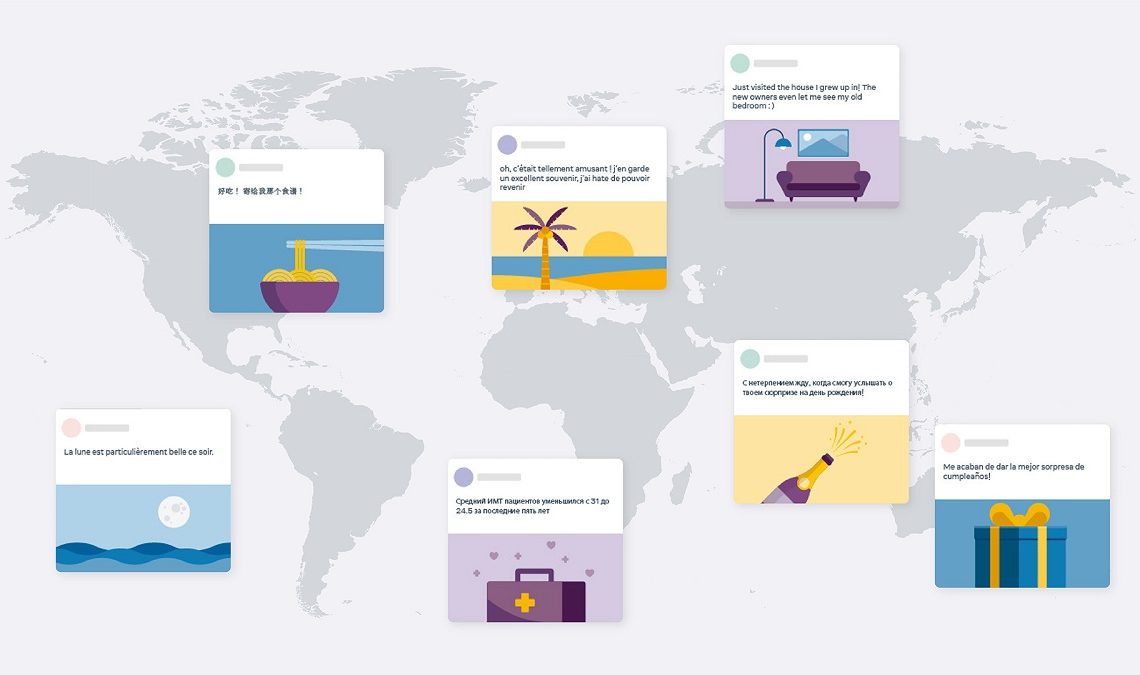
Facebook has announced its new machine learning translation model, which, according to the company, is the first that doesn’t rely on English data. Machine translation is specifically important to the giant social media site, which today performs an average of 20 billion translations every day.
According to the company, nearly two-thirds of all users use other languages apart from English.
The software is open-source, and the company is inviting contributors to build more support on top.
The tool can currently translate any pair of 100 languages independently – without using English as a bridge between the two.
“When translating, say, Chinese to French, most English-centric multilingual models train on Chinese to English and English to French, because English training data is the most widely available,” Angela Fan, a Research Assistant in a blog post.
The social media company platform says many Advanced multilingual systems compromise on accuracy when relying on English as a bridge. But with one on one language translations, the software can better preserve meaning.
The new model was created out of a need to serve its massive and diverse community of users better.
“Facebook AI’s new many-to-many multilingual model is a culmination of several years of pioneering work in MT[Machine Translation] across breakthrough models, data mining resources, and optimization techniques,” Fan wrote.
The new machine learning will help the company improve its content delivery to its two billion-plus users worldwide in over 160 languages. For a start, the new model ushers a new path for the company as it aims to build a single universal model that can understand all languages across different tasks.
Read Next: Audio and Video Calls are Coming Soon on WhatsApp’s Desktop App